用機器學習的方式登入選課系統
之前大三上剛開學的時候閒閒沒事,剛好那段時間正在選課,有鑑於每次登入選課系統都要打驗證碼(下圖),我自己是覺得很麻煩(到底有多懶),就想說用 Python 寫個自動登入的程式,不過選課系統的數字驗證碼長得不是很好看,去暴力搜尋每個數字感覺不太可行,後來決定先用 OpenCV 把數字切出來,再用機器學習去辨識數字,一開始寫的時候是直接用 tensorflow 的手寫數字辨識 CNN 模型,不過因為 MNIST 的手寫數字跟選課系統的數字驗證碼書寫風格差異有點大,加上那時候用 OpenCV 做 preprocessing 理弄得亂七八糟(雖然現在的版本可能還是亂七八糟),所以數字辨識的準確度只有 85% 左右,根本沒辦法拿來登入選課系統,因為其中一個數字打錯就整個都錯了。
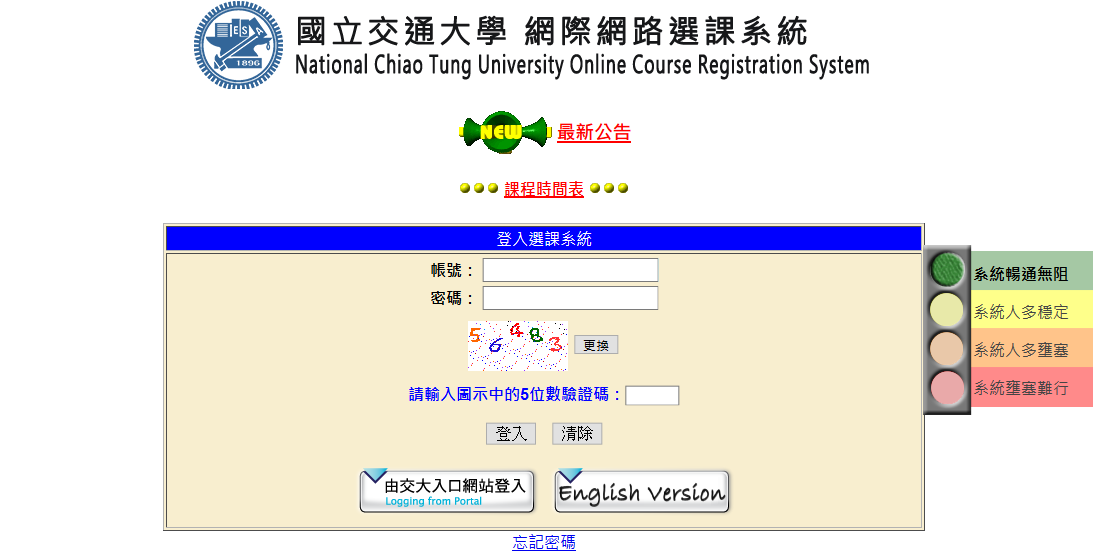
之後事情開始變多,得念書考試寫作業,只好把這個東西暫時擱置,一直等到現在大四上結束,才有空繼續把它完成。下面的介紹主要就分成實作方法跟實驗結果兩個部分。
實作方法
開發環境
- Windows 10 Home
- Python 3.6.4
- Python packages: OpenCV, Numpy, Pillow, Requests, scikit learn, Selenium
蒐集 training data
這邊就簡單地用 requests 來抓圖片,一共下載了 7000 張。
1 | import requests |
Preprocessing
我們用這下面張圖來解說。

首先會把驗證碼統一調整大小至 50 乘 100,然後把驗證碼加白框(怕數字太靠近圖片邊緣,之後在切割的時候會不好處理),再來把圖片轉乘灰階,因為有些數字的顏色較淺,轉乘灰階之後還要利用 adaptiveThreshold 把數字從背景中分離出來。
1 | image = cv2.imread(filename) |

如上圖所示,這時候的圖片還是有雜訊(背景的黑點點),根據 OpenCV Python Tutorial 上面有關 Medium Filtering 的介紹:
This is highly effective in removing salt-and-pepper noise
接著用 medianBlur 來去除背景的雜訊。
1 | image = cv2.medianBlur(image, 3) |
處理完後會像下面這個樣子,仔細觀察其實可以發現在降噪的過程中,「3」跟「9」有部分筆劃感覺也被去除了,這部分我現在還想不到可以怎麼改善,我相信一定有更好的處理方法,如果讀者有什麼想法也可以留言或寫信告訴我。
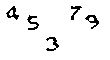
切割數字
把雜訊去掉後,下一步就是把驗證碼裡面的數字切割出來,OpenCV 有個很方便的函數 findContours 可以直接將輪廓標出來。
1 | contours, hierarchy = cv2.findContours(img_blur_gray, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) |
findContours 有三個主要的參數,第一個當然就是要被檢測的圖片,第二個是 mode,用來指定要使用哪種模式檢測輪廓,我們使用 cv2.RETR_TREE 來建立一個樹狀結構的輪廓,第三個參數是 method,用以選擇輪廓的近似方法,如果用 cv2.CHAIN_APPROX_NONE 的話,OpenCV 會將輪廓上的所有點存下來,假如今天碰到一個矩形的輪廓,那矩形的四條邊都會被存起來,但其實我們只要知道四個頂點的座標就夠了,所以改用 cv2.CHAIN_APPROX_SIMPLE。
接著來看 findContours 回傳的資料,該函數會回傳兩個東西,一個是輪廓本身(contours),一個是每個輪廓對應的屬性(hierarchy),contours 裡面包含每個輪廓的點,如果是矩形輪廓就有四個點,五角形就有五個點,依此類推;hierarchy 則是輪廓的樹狀結構,每個輪廓都對應到其中的四個元素,分別是「後一個輪廓、前一個輪廓、父輪廓、被自己包起來的輪廓編號」。
這邊我們只會使用到 contours,首先用 drawContours 把輪廓畫出來看看:

可以發現偵測到的輪廓是多邊形,但是我們的目的是要切割出數字所在的矩形區域,可以用 boundingRect 來算出包含整個輪廓的最小矩形。
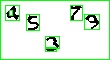
算完後會長這樣,相信大家也注意到了,上圖的「4」會有兩個輪廓,一個是「4」的外圍的輪廓,一個是「4」中間空洞的輪廓,用 boundingRect 計算完後會產生兩個矩形,就是分別對應這兩個輪廓,但是只有外圍那個才是我們想要的,所以還要加一些判斷式來檢查,最後的程式碼會長這樣。
1 | valid = [] |
這邊還有一點要注意,可以看到上圖的「3」被切成兩個部分,之所以會這樣可能是與先前提到降噪的問題有關,為了解決這種情況,我另外寫了一個用來合併矩形的函數。因為當這種情況發生時,兩個矩形通常會有部分區域重疊(上圖的「3」就是這樣),至於實作方面,我們可以透過 logical AND 來檢查是否重疊,每個矩形都對應到一張 60 乘 110 的圖,矩形所在的地方標「1」,其他地方標「0」,把兩張圖做 AND 就知道有沒有相交了,下面是合併矩形的程式碼。
1 | contours.sort(key=lambda x: x[0]) |
簡單說明一下,前五行先把矩形由左到右排序,並畫出每個矩形對應的 60 乘 110 的圖,第七行的 state 是用來記錄該矩形處理了沒,因為矩形已經排序過,所以第 i 個矩形只可能與第 i + 1 個相交,如果相交的話就將兩者合併,並在 state 中將第 i 與 i + 1 個紀錄為已處理的狀態。注意第 22 行的判斷式,因為有時候會發生兩個數字靠很近,導致矩形相交,這時就要檢查矩形的大小,如果超過單一數字的矩形大小(這邊設定為 20),就代表過程中誤將兩個數字合在一起了,不應該採用該合併後的結果。下圖是合併之後的結果。
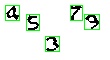
Train model
每張驗證碼會切出五個數字,7000 張驗證碼總共有 35000 個數字,切割完數字後就可以開始訓練辨識用的模型了,一開始是想用 unsupervised learning 的方式去學習,畢竟切出來的三萬多張圖也沒有標 label,想說讓電腦自己去做 clustering,於是就用 scikit learn 提供的 KMeans 來訓練模型,但是做出來的準確度有夠低,一方面是因為 KMeans 只能找 local minimum,如果初始化爛掉了那就很可能會繼續爛下去,另一方面是有些數字其實長得很像,像是「3」寫醜一點就很像「8」,或許改用 Spectral Clustering 會比較好一點,不過後來還是決定先用 supervised 的方式,Spectral Clustering 之後有空再說。
因為改用 supervised,所以我自己手動標了 700 張數字,每個數字各 100 張(驗證碼只會出現 3、4、5、6、7、8、9 這七種數字),然後用 scikit learn 的 SVM 來訓練。
1 | def train() |
訓練完第一版模型之後,我打算用這個模型來處理剩下的 34300 張數字,主要流程就是 SVM 每標註完 2000 張數字後,會訓練一個新版本的 SVM,再用這個新的模型去標註,一直重複這些動作直到所有圖片都標好 label,我那麼懶怎麼可能自己手動跑這些步驟呢,當然是直接寫 Python 讓電腦全部自己完成,以下是程式碼。
1 | model = train() |
全部跑完之後發現這七個數字的出現頻率都還滿平均的,每個數字大約出現五千次左右,至於準確度的部分我並沒有特別去測,不過整個流程跑完之後我有去檢查每個 label 所在的資料夾,35000 張數字只有不到 5 張被放錯地方(標錯 label)。
登入系統
模型訓練好後,就可以開始嘗試登入選課系統了,不過第一個碰到的問題就是如何從網頁畫面中取得驗證碼,因為驗證碼是透過 https://course.nctu.edu.tw/function/Safecode.asp 隨機產生的,沒辦法直接用 requests 從網頁裡面抓圖片,或許 Python 有辦法抓網頁載入時後台的資訊,但是我不知道怎麼做 QQ,所以後來決定直接把視窗 resize 成固定大小,再用 Selenium 抓特定的區塊,接著就是把抓到的驗證碼丟給切割數字的函數,再把切出來的五個數字拿去辨識,這部分的程式碼因為沒有什麼比較需要解釋的,只是一些 Selenium 的操作(自動點擊、輸入文字等),所以就不放上來了。
實驗結果
下面是我錄的小短片,驗證碼的辨識準確度跟辨識速度都有不錯的表現,我後來也寫了一個簡單的 BAT 檔,要登入的時候點兩下就好了,整體下來感覺還不錯,但就是敗在 Selenium 的開瀏覽器的速度,如果能夠再快一點就好了。然後程式碼的部分我都放在 Github 上面了,有興趣的讀者可以去玩玩看,有什麼問題或想法也歡迎寫信告訴我。