[爬蟲] PTT - 3
之前已經說明如何取得單一頁的文章列表,還有如何分析文章頁取得內文,想複習的話可以看看這兩篇文章,爬蟲 / PTT - 1、爬蟲 / PTT - 2,今天要討論如何透過討論版總頁數取得 10 頁、50 頁甚至近千頁的文章列表頁網址。
環境
- Windows 10 Home
- Python 3.6.4
取得討論版總頁數
我們先觀察文章列表頁的網址,以八卦版為例,到八卦版首頁點選”上頁”,網址末端的數字是 37092,再往上頁看,變成 37091,或者直接跳至”最舊”,數字變成 1,發現到我們可以經由網址末端的數字得知該版的總頁數,最舊的那一頁就是 1,一直往上累加到目前的頁數也就是最新的一頁,所以只要能得到總頁數,就能得到每個列表頁的網址。
取得網頁原始碼
一樣使用 request.get 拿到八卦版首頁的原始碼,然後再用 BeautifulSoup 包起來。
1 | res = requests.get( |
分析原始碼,取得總頁數
先打開瀏覽器到八卦版首頁按下 f12 觀察一下,「最舊、上頁、下頁、最新」這幾個按鈕被包在 class="btn-group-paging" 底下的 class="btn" 裡面。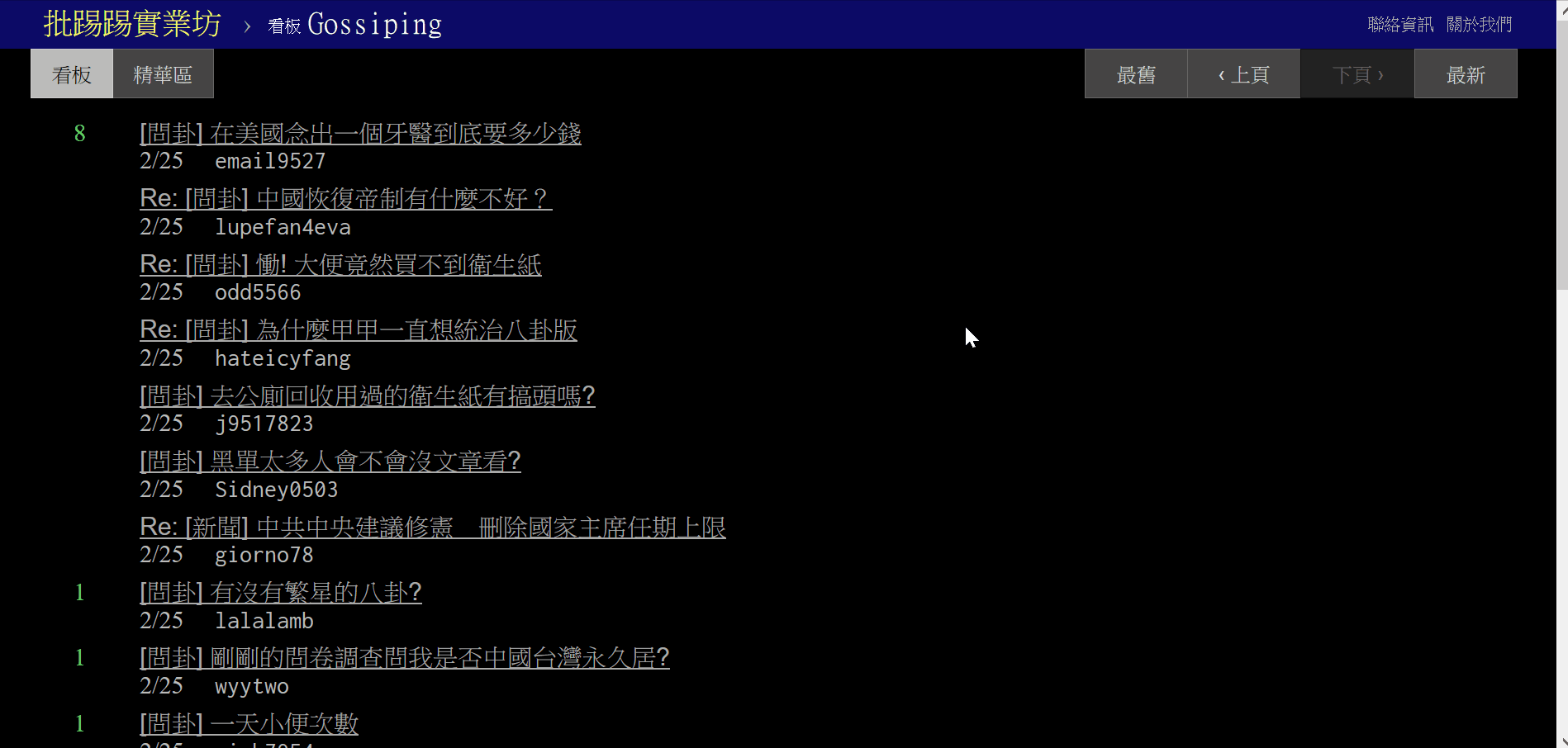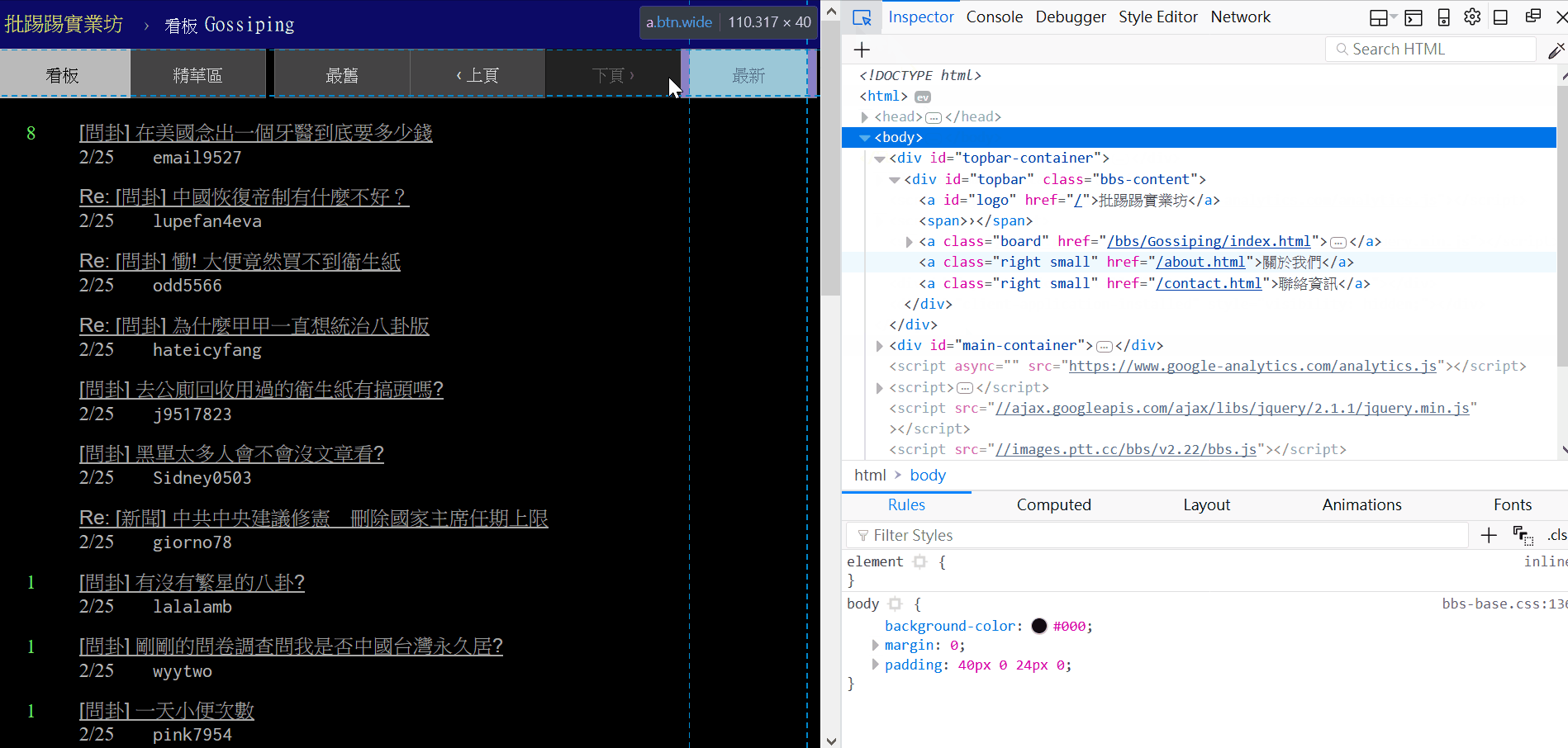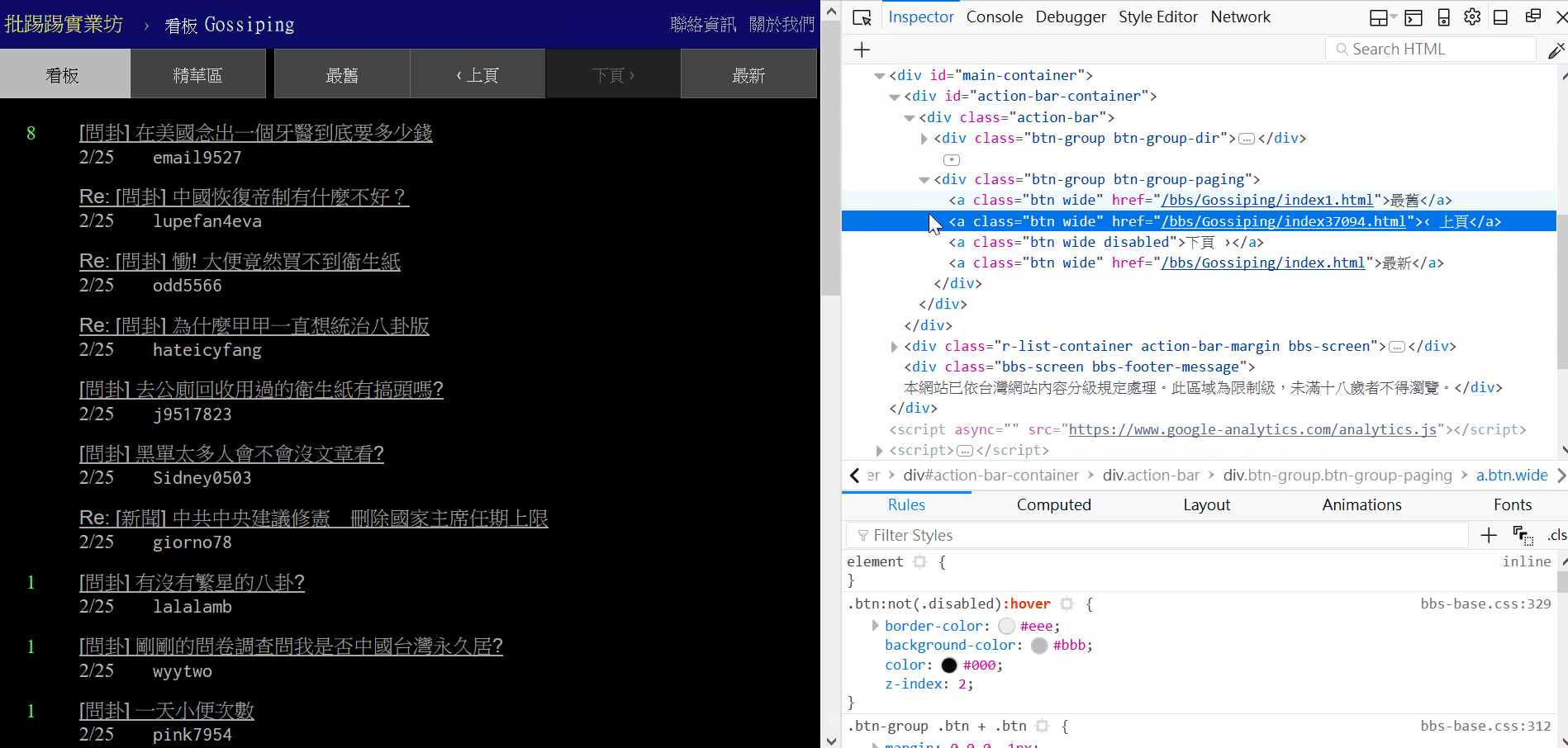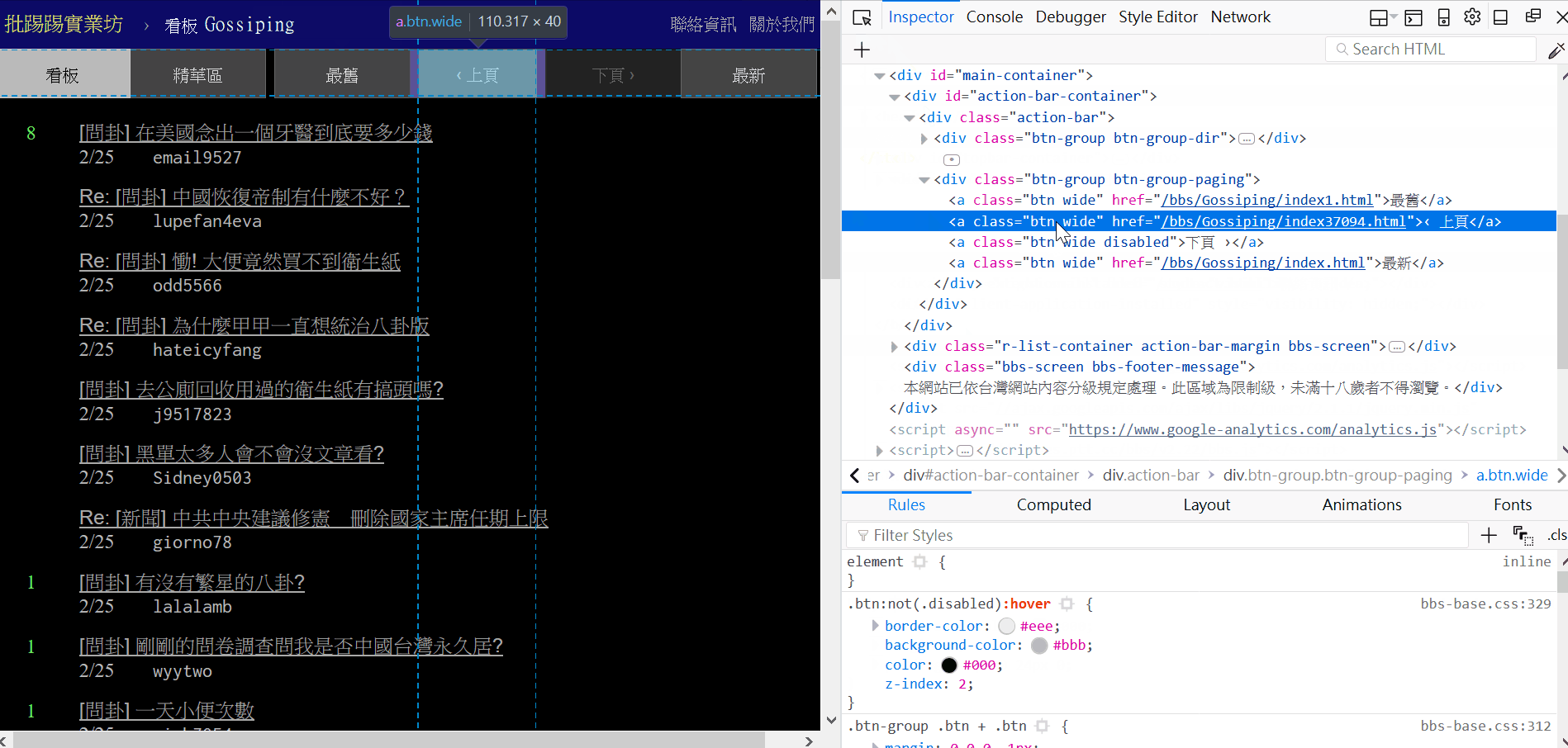
1 | pagination = content.find('div', {'class': 'btn-group-paging'}).find_all('a', {'class': 'btn'}) |
「上頁」在第二個 class="btn" 裡面,所以是 pagination[1],取出「上頁」的連結後把前面 ‘/bbs/Gossiping/index’ 這段字串拿掉 (用 replace 替換成空字串就好了),然後第四行這邊用到了 Python 的 slice 把字串尾巴的 “.html” 移除,剩下來的部分就是數字了,不過現在的數字是 string 型態,要轉換成 int 才能夠做加減的動作,這邊為什麼還要加一呢?因為我們抓到的數字是最新一頁的”上頁”的,所以還要加一才會是目前的總頁數。
取得文章列表頁網址
有了總頁數就可以得到每個文章列表頁的網址了,上面講過最舊頁是 1,一直累加上去到最新頁。假設現在有 100 頁列表,那最新的一頁就會是 100,假設我們想爬 20 頁,寫成 C 大概會長這樣:
1 | for (int i = 100; i > 100-20; i--) { |
在 Python 裡面可以用 range() 來達成,想深入了解 range() 用法的話可以到 Python Built-in Functions 看。
上面的 C 寫成 Python 的 range() 就是:
1 | for i in range(100, 100-20, -1): |
range() 裡面第一個參數放的是開始的值,第二個是結束的值,第三個是每一步的間隔,第三個可放可不放,預設是 1。range(100, 100-20, -1) 的意思就是從 100 開始,到 100-20 也就是 80 結束 (不包含 80),第三個參數 step 設成 -1 就是每次遞減 1 的概念,所以如果把 range(100, 100-20, -1) 印出來就會得到從 100 到 81 這 20 個數字。
有了總頁數、知道如何使用 range(),我們就可以很簡單的取得每個文章列表頁的網址了
1 | links = list() |
現在已經可以利用總頁數來得到我們要爬的 10 頁、20 頁或者更多頁的文章列表頁網址,再來就要針對諸多列表網址中的每個網址去取得每頁的文章連結了,不過講到這裡先告一段落,剩下的我們下面幾篇再來慢慢談。