應徵上國網中心工讀生之後第一件事就是練習 Python 爬蟲,爬 PTT、facebook、MOBILE01 這類的論壇,這幾天正在做 PTT 的部分。
環境
- Windows 10 Home
- Python 3.6.4
安裝 library
- Requests (取得網頁原始碼)
- BeautifulSoup4 (處理網頁原始碼)
1
| pip3 install beautifulsoup4
|
如何取得文章列表
取得網頁原始碼
先把要用到的 library import 進來
1
2
| import requests
import BeautifulSoup
|
1
2
3
4
5
| res = requests.get(
url='https://www.ptt.cc/bbs/Gossiping/index.html',
cookies={'over18':'1'}
)
html = res.text
|
requests 可以處理一般 service 的請求,requests.get 裡面有很多參數,url 就是我們要抓的頁面的網址,這邊設定 cookies 的用意在於 PTT 有些版會要求年齡 18 歲以上才能進入,我們將 over18 設為 1(已滿 18 歲)並存入 cookies。
以八卦版為例(八卦板首頁網址為 https://www.ptt.cc/bbs/Gossiping/index.html),`requests.get` 會回傳一個 Response 物件,透過 .text 可以取得網頁原始碼。
我們把 html 印出來看看,應該會長這個樣子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| <!DOCTYPE html>
<html><head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<title>看板 Gossiping 文章列表 - 批踢踢實業坊</title>
<link href="//images.ptt.cc/bbs/v2.22/bbs-common.css" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.22/bbs-base.css" media="screen" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.22/bbs-custom.css" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.22/pushstream.css" media="screen" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.22/bbs-print.css" media="print" rel="stylesheet" type="text/css"/>
</head>
<body>
<div id="topbar-container">
<div class="bbs-content" id="topbar">
<a href="/" id="logo">批踢踢實業坊</a>
<span>›</span>
<a class="board" href="/bbs/Gossiping/index.html"><span class="board-label">看板 </span>Gossiping</a>
<a class="right small" href="/about.html">關於我們</a>
<a class="right small" href="/contact.html">聯絡資訊</a>
</div>
</div>
<div id="main-container">
<div id="action-bar-container">
<div class="action-bar">
<div class="btn-group btn-group-dir">
<a class="btn selected" href="/bbs/Gossiping/index.html">看板</a>
<a class="btn" href="/man/Gossiping/index.html">精華區</a>
</div>
<div class="btn-group btn-group-paging">
<a class="btn wide" href="/bbs/Gossiping/index1.html">最舊</a>
<a class="btn wide" href="/bbs/Gossiping/index37017.html">‹ 上頁</a>
<a class="btn wide disabled">下頁 ›</a>
<a class="btn wide" href="/bbs/Gossiping/index.html">最新</a>
</div>
</div>
</div>
<div class="r-list-container action-bar-margin bbs-screen">
<div class="r-ent">
<div class="nrec"></div>
<div class="mark"></div>
<div class="title">
<a href="/bbs/Gossiping/M.1519527707.A.3EF.html">[新聞] 主人「暴斃」測忠誠度 喵皇反應讓人笑翻</a>
......太多了,後面省略
|
分析原始碼,取得文章列表
首先在瀏覽器打開 https://www.ptt.cc/bbs/Gossiping/index.html ,按 f12 就可以看到網頁原始碼還有其他資訊,經過觀察發現每篇文章都是包在 class="r-ent" 這個 div 之下。
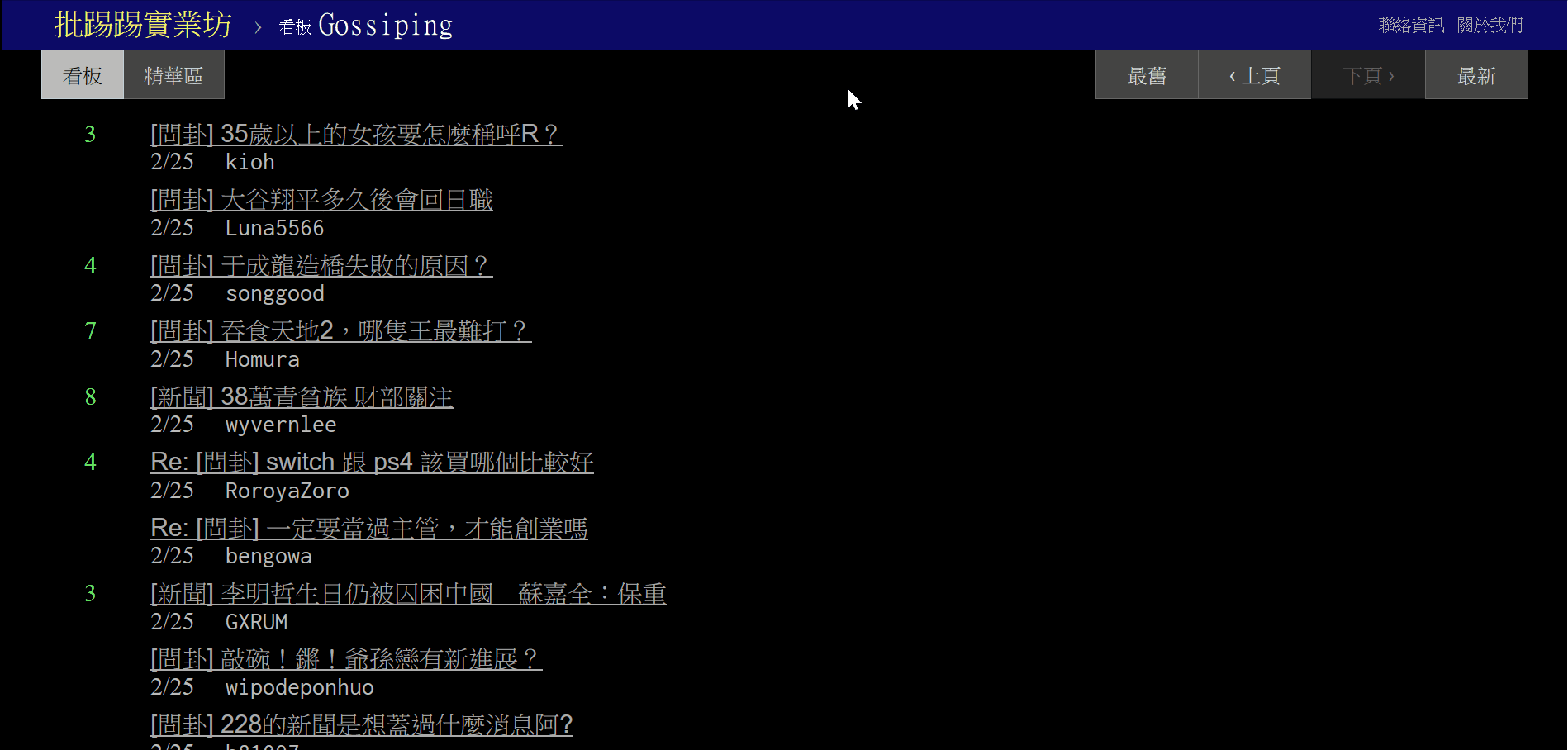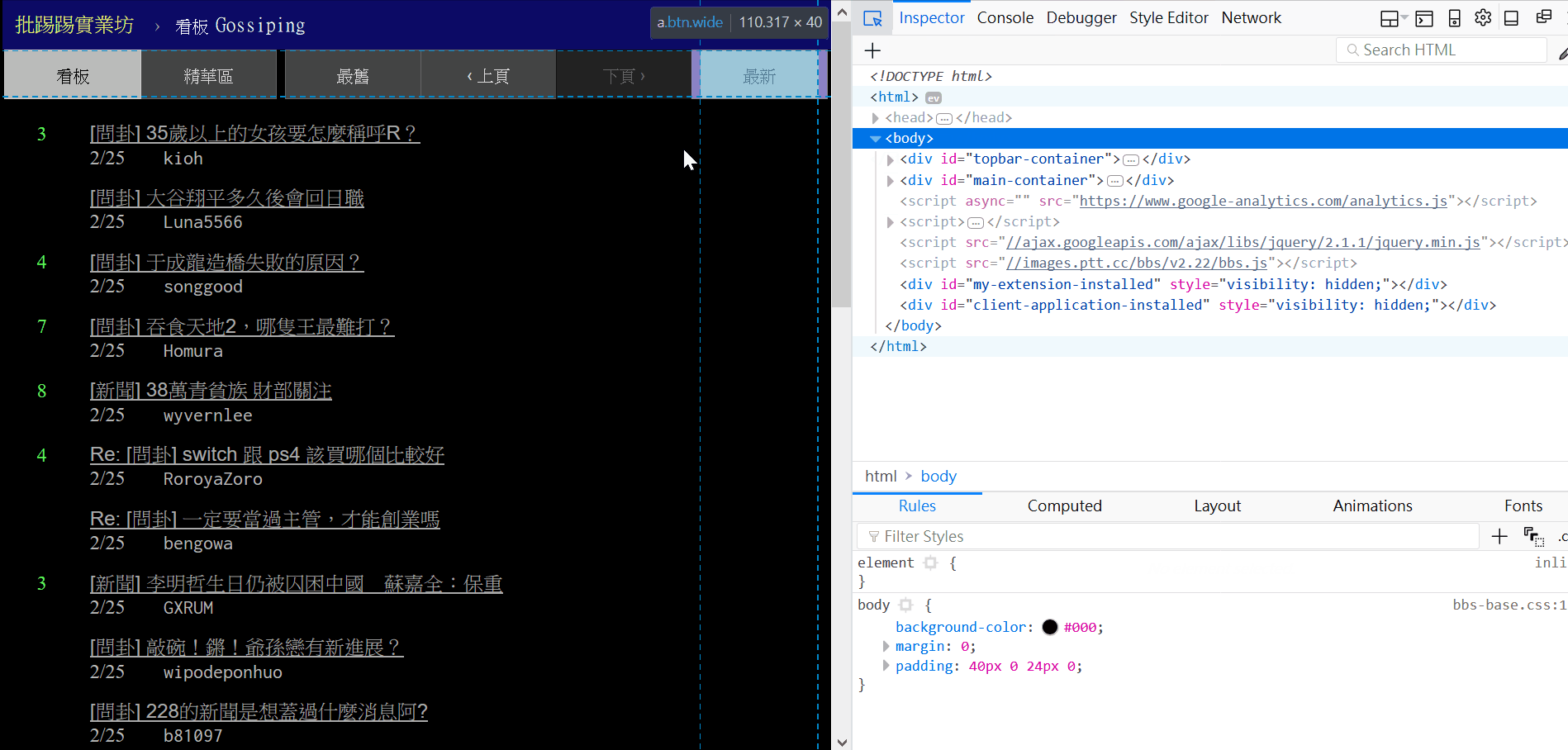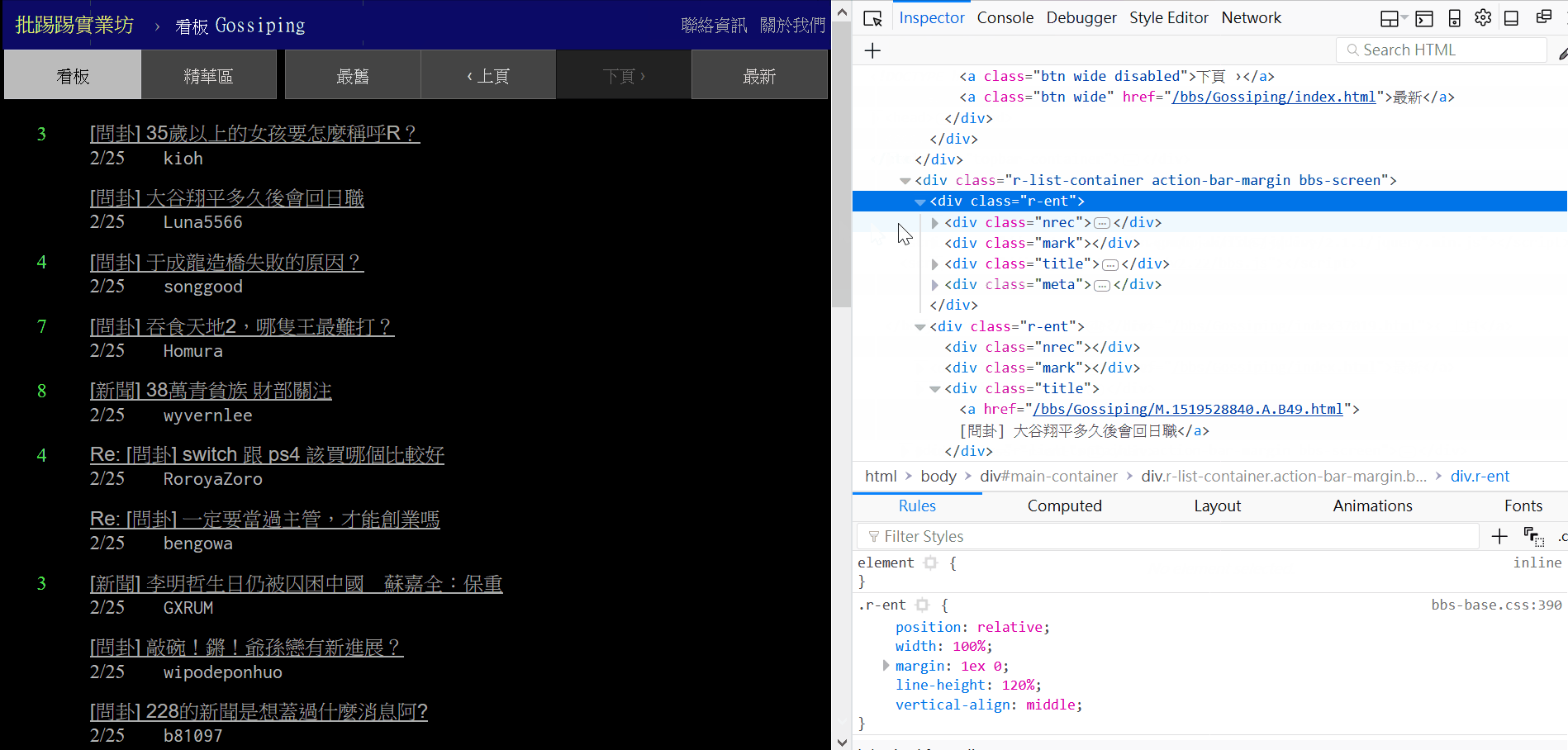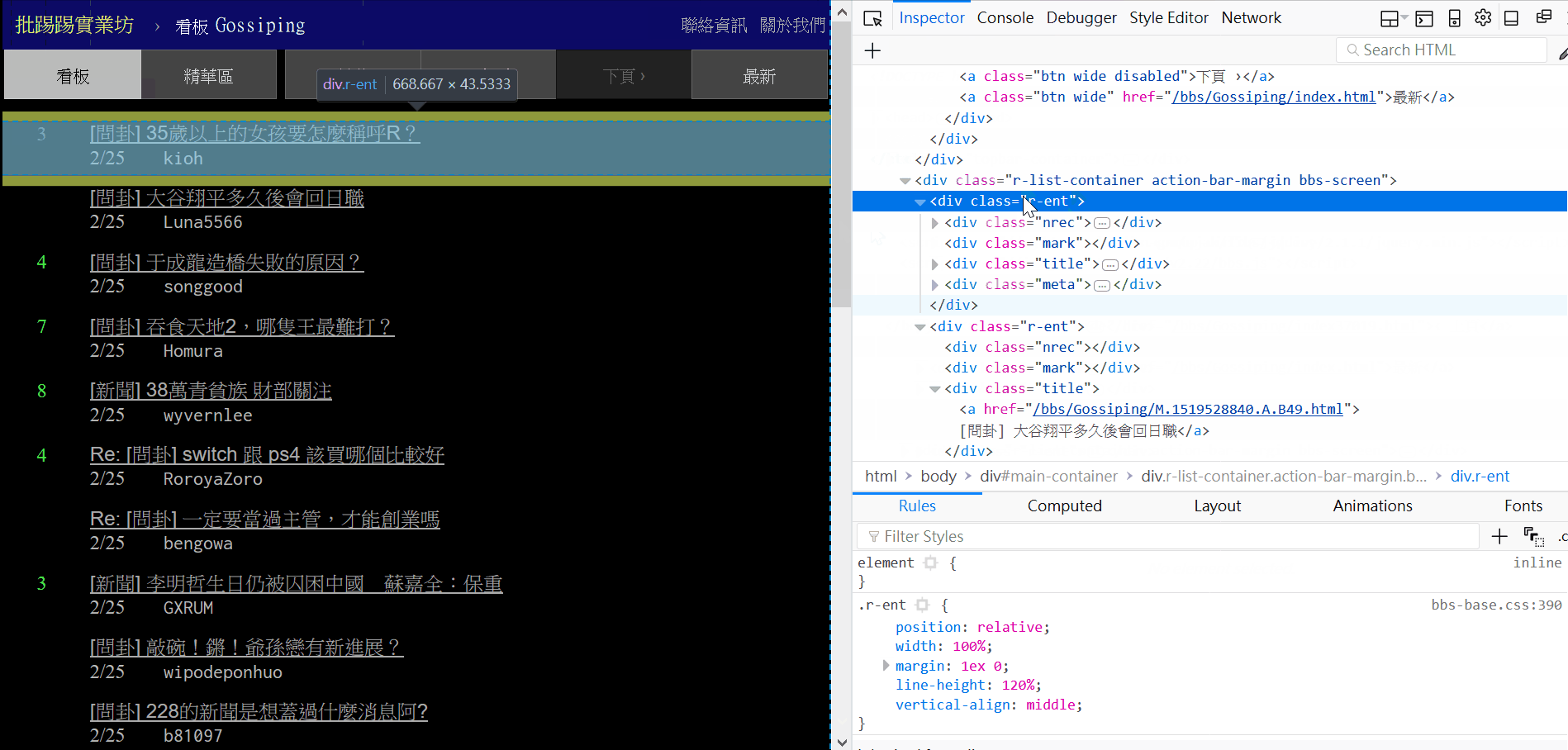
接著用 BeautifulSoup 來提取原始碼中我們要的部分,因為要找出所有符合 class="r-ent" 的 div,所以用 find_all (如果用 find 只會找一個),find_all 會回傳可迭代的 ResultSet 物件,可以用 for loop 看看他裡面是什麼。
1
2
3
| rows = html.find_all('div', {'class': 'r-ent'})
for row in rows:
print(row)
|
執行出來的結果應該會是這樣,很多個由 class="r-ent" 包起來的 div
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| <div class="r-ent">
<div class="nrec"><span class="hl f2">4</span></div>
<div class="mark"></div>
<div class="title">
<a href="/bbs/Gossiping/M.1519530046.A.17E.html">[問卦] 雪爾80的副駕駛有用嗎?</a>
</div>
<div class="meta">
<div class="date"> 2/25</div>
<div class="author">kobe9527</div>
</div>
</div>
<div class="r-ent">
<div class="nrec"><span class="hl f2">6</span></div>
<div class="mark"></div>
<div class="title">
<a href="/bbs/Gossiping/M.1519530052.A.6B9.html">[問卦] 有沒有參加法會佛像有怪聲的八卦</a>
</div>
<div class="meta">
<div class="date"> 2/25</div>
<div class="author">SagaCandida</div>
</div>
</div>
......太多了,後面省略
|
從上面的 html 程式碼可以發看到每篇文章的連結都在 class="title" 的 div 裡面,剛剛說過 ResultSet 這個物件是可迭代的,所以使用 for loop 來取得每篇文章的資訊。
1
2
3
4
5
6
7
8
9
10
11
12
| posts = list()
for row in rows:
meta = row.find('div', 'title').find('a')
if meta :
posts.append({
'link': meta['href'],
'title': meta.text,
'date': article.find('div', 'date').text,
'author': article.find('div', 'author').text,
'push': article.find('div', 'nrec').text
})
|
這邊為什麼用 find 而不是 find_all,因為每個 row 裡面只會有一個 class="title"。
接著利用 ['href'] 可以取得 class="title" 裡面的連結,.text 可以提取出 block 裡面的文字,再將這些資訊一一存入 list 中。
目前為止我們已經可以從文章列表抓出我們要的每天文章的資訊了,現在只有抓一頁文章列表, 後面幾篇文章會講如何抓很多頁以及如何進一步取出每篇文章的內文。